By pull-down menu:
For this example run, we are using multiple input text files (200 abstracts based on search term "prostate cancer") that were fetched from the NCBI PubMed bibliosphere. Text mining was used to develop 10 "concept clusters" based on document word frequency, stopping, and stemming. To perform the run, in the Analysis pull-down menu, select Text Mining, then Multiple text-file input, then Concept clusters via Word Frequency, Stopping, Stemming:
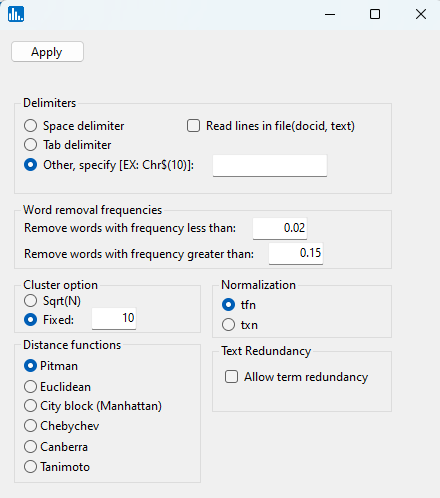
You will then see the following popup window for parameter selection, so accept the default values, and click on Apply:
Once you click on Apply, the file-open window will appear. Search for the folder with small text files in it, and once located, double-click on one of the text filenames:
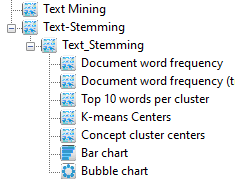
As soon as you double-click on a single filename, the files will be read, and the run will start. When the run has completed, the following output icons will appear:
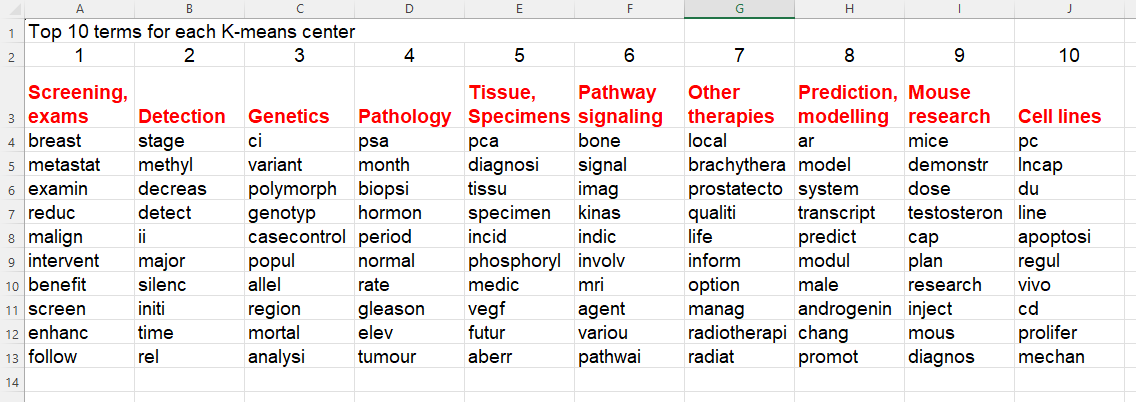
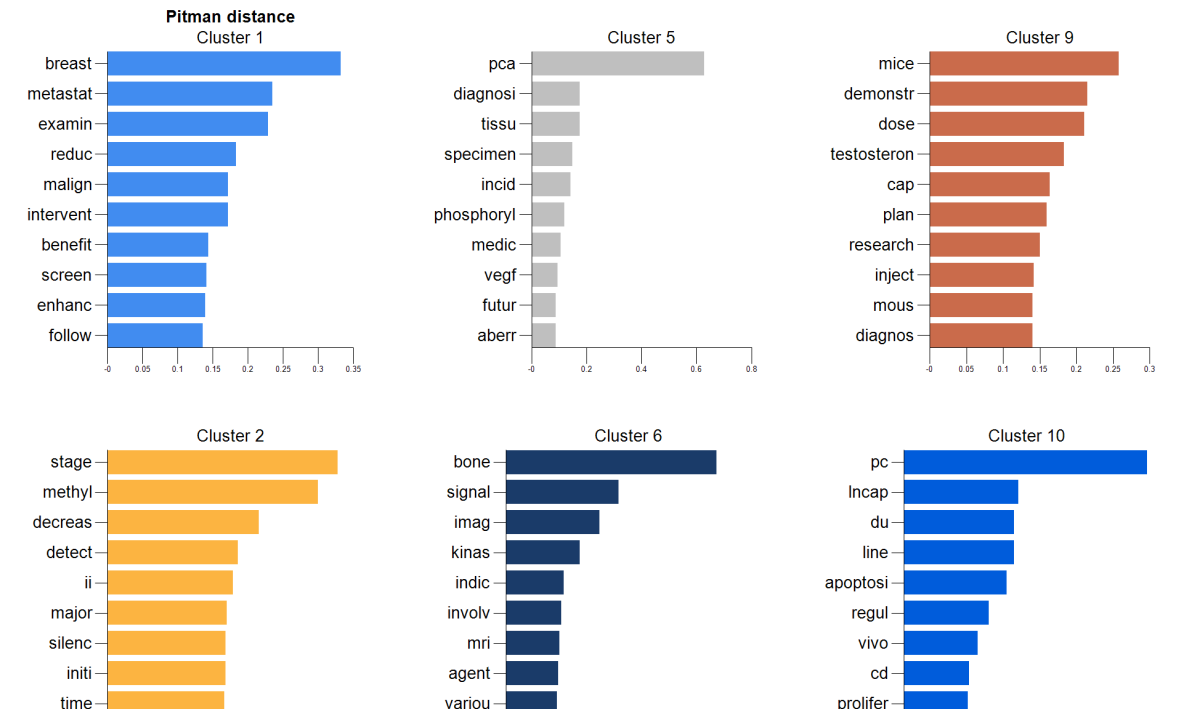
The images below show the result for clicking on the various output icons:
Top 10 words per cluster. For the concept clusters derived, the words colored in red are suggested words that were manually added to reveal what each cluster possibly represents. This is obviously open to interpretation, and such an approach requires expert knowledge in the space of information that was retrieved.