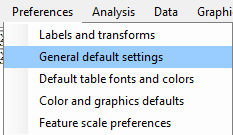
To begin, for most text mining runs it's recommended to turn of the default methods which remove special characters from Excel file inputs. Thus, select Preferences, then General default settings:
Uncheck the checkbox shown below:
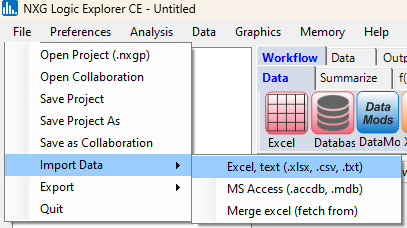
Next, select File, then Import data, then Excel:
Select the radiobutton on the top left, for an Excel file with feature names in the first row:
Open the NCI60_Drug_Screen_Data.xlsx data file, which is distributed with Explorer CE:
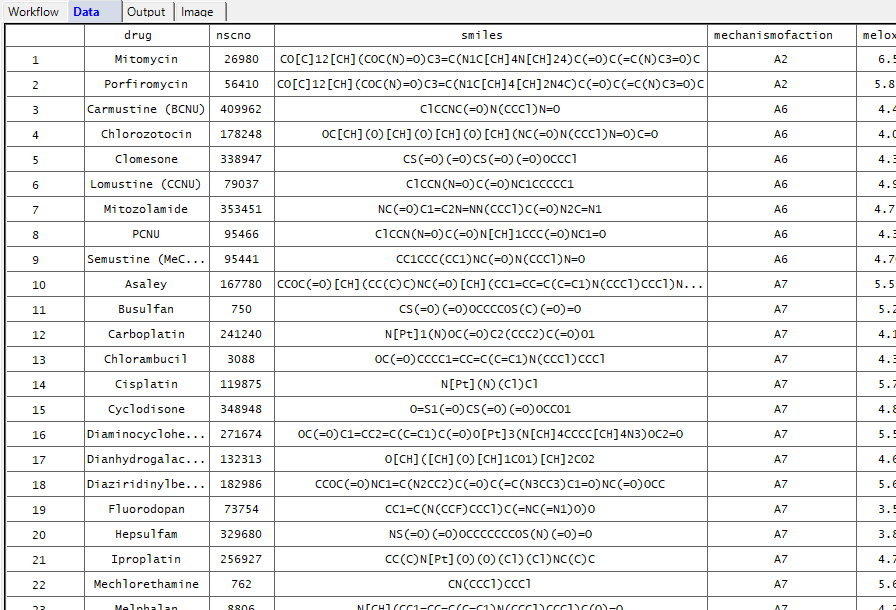
Once the data have loaded, you will be able to see them in the datagrid:
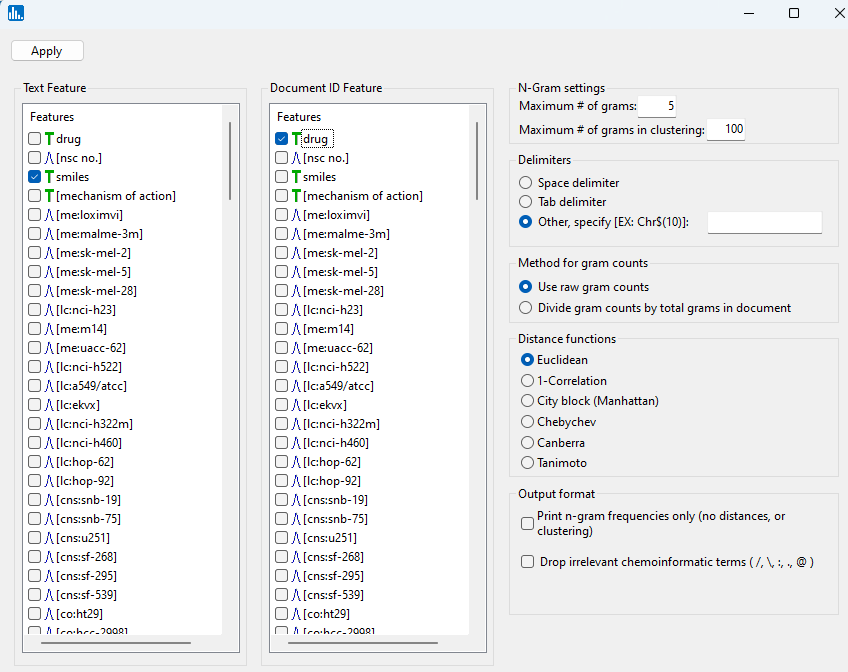
From the Analysis pull-down menu, select Text Mining, then DataGrid input, then One record per document: N-grams:
Select drug as the record ID name and smiles as the text feature to be mined via N-grams. Accept the default values for the other parameters.
When the run has completed, the following icons will be visible:
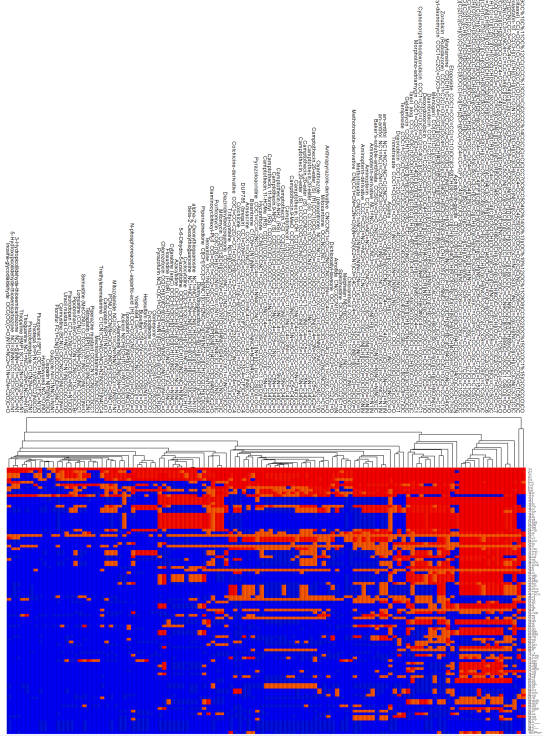
Click on the Heat map icon, and you will notice a cluster image of the N-grams (on the right column), and the SMILES strings at the top arranged arranged vertically. Use your mouse wheel to zoom in on the image, and use the scroll bars on the edge of the image window to pan left-right or up-down.
Below is an image that's zoomed in on the right side of the heat map. All of the SMILES strings (i.e., documents) will be shown in the cluster heat map, but the default for the number of N-grams was 100 (see above), so on the right side of the heat map there will only be 100 N-grams listed. A descending sort is also perfromed, so the 100 N-grams selected for clustering will have the greatest sum of N-gram counts across the documents (SMILES strings).
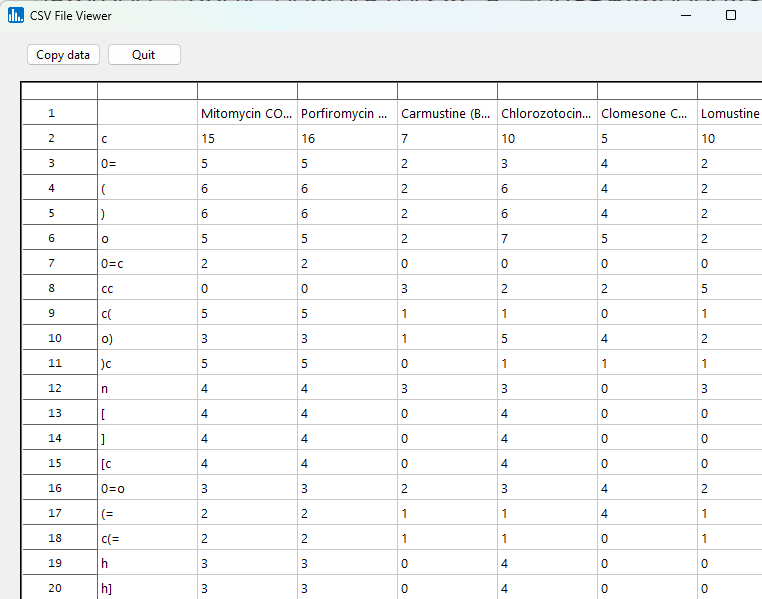
If you click on the Symmetric word frequencies icon you'll see the N-grams in rows, and the counts for each document (drug). These data could be copied and pasted into a new Excel file, saved, and then used externally for other analyses.